
[Recap] Optimizing the databases at Quora
Lessons Learned from Quora's Database Optimization Journey

Reference: https://quoraengineering.quora.com/Optimizing-the-databases-at-Quora
Background
Quora Database load tends to increase over time due to various reasons:
Growth in the number of users and engagement.
Data size increase over time.
New features being launched
Spammers and bad actors
The 3 main parts of the database load
Reads
Data Volume
Writes
1. Optimizing reads
Different kinds of reads need different optimizations:
Complex queries like joins, aggregations, etc
count queries with WHERE clause but without any GROUP BY => materialized the counts in another table.
Large scans => use LIMIT or use pagination.
Misalignment between schema and query
Removing unnecessary columns in the select clause.
Removing an order by clause, and sorting on the client instead (MySQL CPU > Client CPU)
Removing the query altogether if the functionality being provided by that query is no longer important.
Is inefficient caching causing the high QPS queries?
If the cache key is too specific or narrow, it can cause high QPS to the database.
If the cache key is too broad, it causes a lot of data to be pulled from the database in each query.
Query on user languages table
Requirement: Query the database to see if user U uses a language L.
CREATE TABLE language_tab (
user_id INT,
language_id INT
);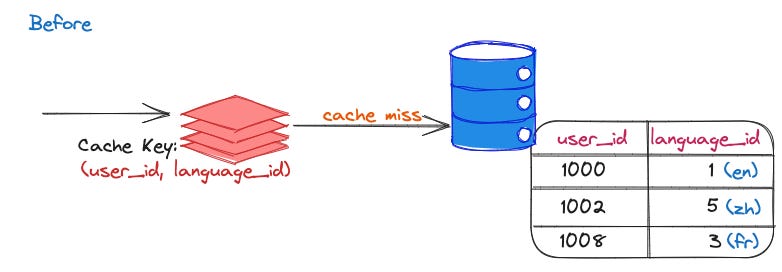
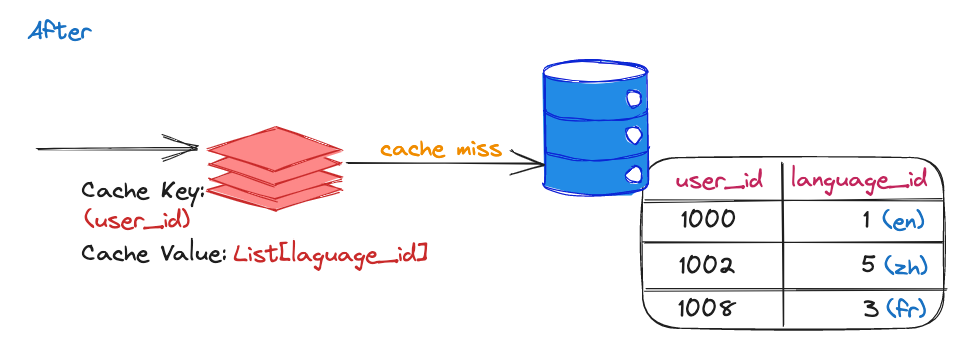
A table with user language info had a high query rate, mostly returning empty results due to most users only using one or a few languages. => The cache key was changed to just user_id. This increased the amount of data pulled from the Database but reduced QPS by over 90%.
Query on A2A table
On Quora, you can request answers for your questions from specific users through an "A2A request" when asking or following a question.
CREATE TABLE A2A_tab (
user_id INT,
question_id INT,
answer_id INT
);Requirements:
Request type 1: Get all answerers that a user has already requested to answer a question.
Request type 2: Get all users that have requested the same answerer to answer a question.
Support high QPS
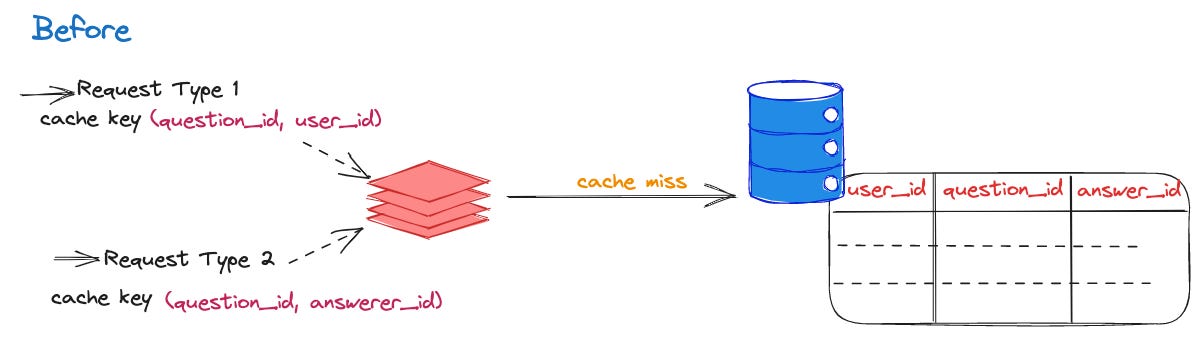
The number of potential cache key is really huge: = Number of questions x Number of users (asker or answerer).
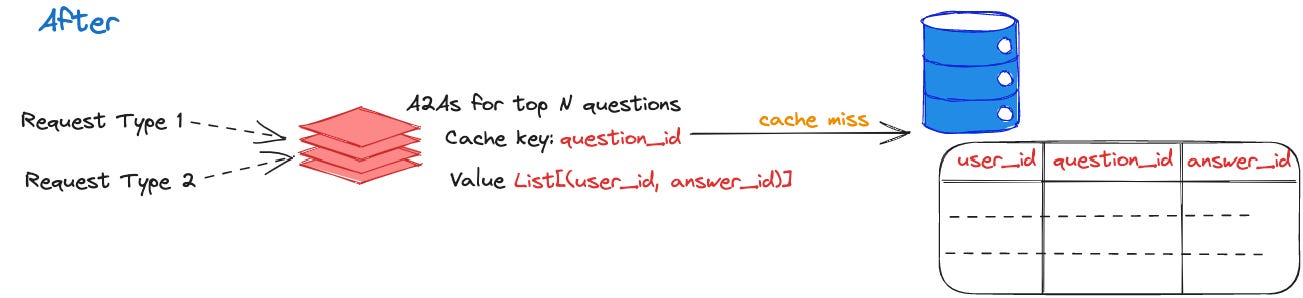
The small number of combinations would actually have data in the table. While most questions had only a few A2A requests, a small fraction of them received significantly more. We added an extra cache that contains the A2As for a question up to a limit N such that we capture most of the questions. This extra cache reduced QPS on the A2A table by 50-66%.
Sparse data sets in one dimension
Requirements:
Querying for whether a question needs to be redirected mostly returns an empty result since only a small percentage of questions are redirected to other questions.
Querying for whether an answer is collapsed mostly returns empty result since most answers are not collapsed.
Notes:
The info such as whether a question is redirected was NOT stored in the main questions table but in a separate table.
The cache key has one major entity such as `question_id` or `answer_id`. Most keys don't have data in the table, it's a sparse data set. => Creating a key with an empty value is efficient.
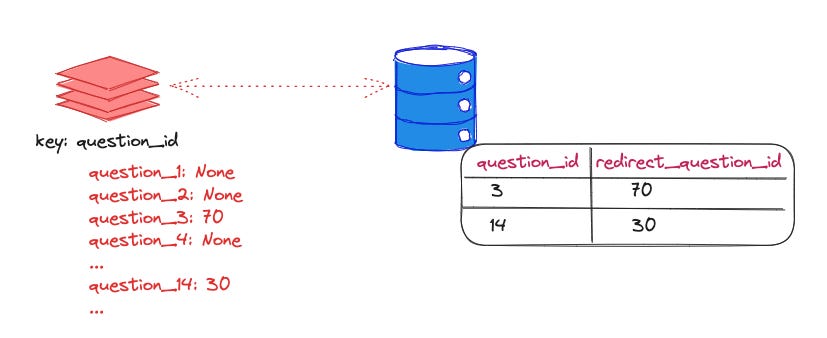
Solutions:
Suppose we query for question_id = q. In the database table suppose q does not exist, but the previous question is q0 and the next question is q2. If we could remember that no questions with ids between q0 and q2 are redirected, that would greatly help future queries that look for question ids in that range.
Use fixed-length ranges.
fixed range length: N
lookup key: K
cache the range query for keys:
>= K - K % N and < K - K % N + N
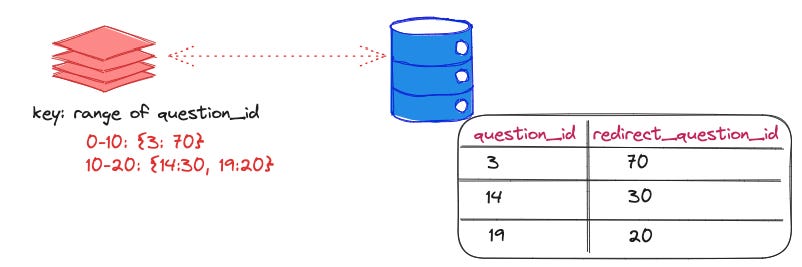
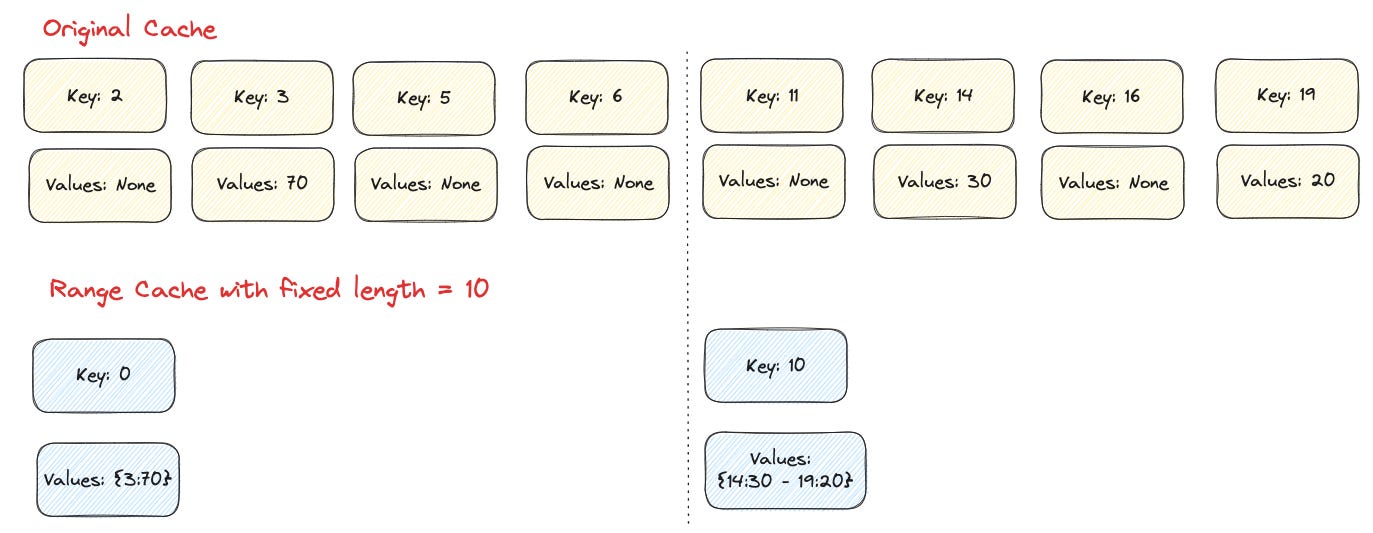
Question: Whether we are trading multiple point queries for one range query that is cost-effective?
The cost of a query includes fixed costs like network round trip, syntax, and semantics checks, processing in the thread pool, look-ups in the B+tree, etc., plus a cost per row processed.
This latter cost is proportional to the number of rows in the range actually existing in the table, rather than the range size. For sparse data sets, the fixed cost is much smaller than the latter.
Therefore, doing many point queries results in a huge fixed cost.
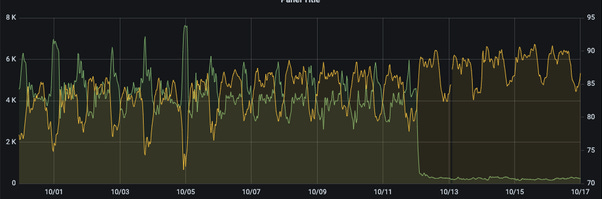
We used range caching to optimize queries on sparse data sets with very high QPS. It was not uncommon to see large reductions in the database QPS of such queries, some over 90%!
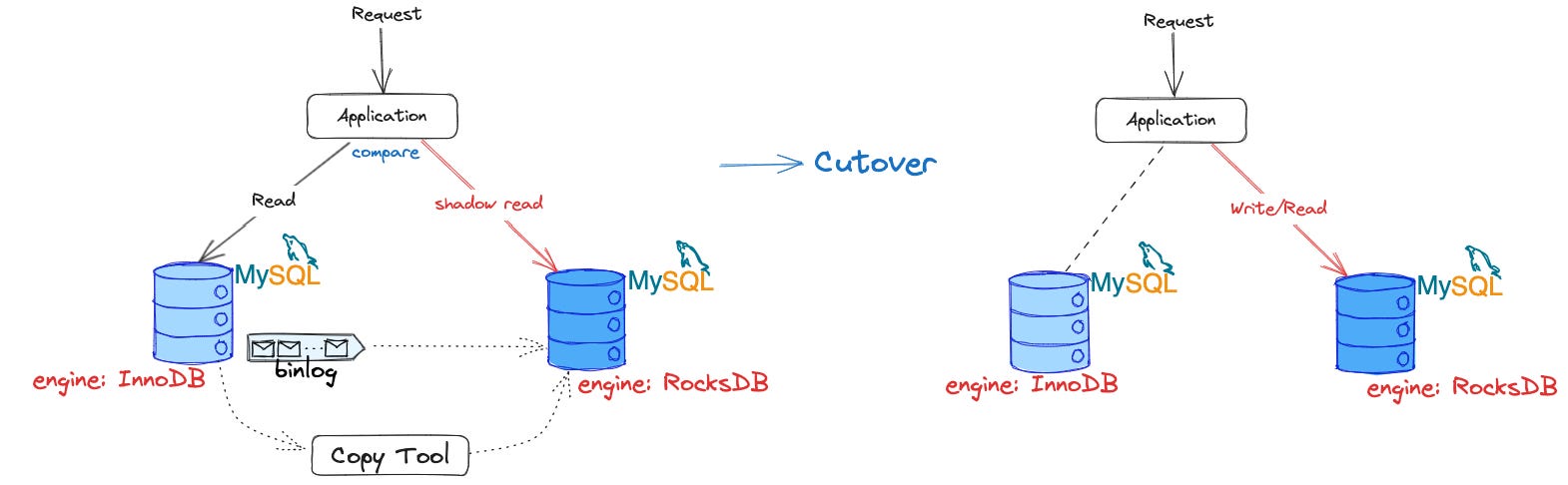
2. Optimizing space used by tables
Using MyRocks engine to reduce table size
Had a tool to move a MySQL table from one MySQL master to another.
3. Optimizing writes
Most of our MySQL tables are not heavy on writes. We see replication lag alerts sometimes, as MySQL replication replays write sequentially on the replica by default, even if they happen concurrently on the master.
MySQL provides two ways of doing this as noted below.
slave_parallel_type=LOGICAL_CLOCK (replica_parallel_type since MySQL 8.0.26)
This has been available since MySQL 5.7. This can parallelize writes on replicas even if all tables are in the same logical database.
slave_parallel_type=DATABASE (replica_parallel_type since MySQL 8.0.26)
This needs tables to be in multiple logical databases to be able to parallelize the writes.
Tables need to be in multiple logical databases for parallelizing writes. However, all tables were created in one logical database in MySQL hosts. To separate logical databases, the zookeeper configuration was enhanced to track the table's logical database, which can be dynamically changed later.
MySQL's alter table statement can change the table's logical database without copying data, and it updates the configuration in Zookeeper.
alter table <logical_db1>.table rename <logical_db2>.mytableOne table was moved to its own logical database, and parallel replication was enabled, reducing replication lag.