


[Recap] Why ZooKeeper Was Replaced with KRaft – The Log of All Logs

Reference: https://www.confluent.io/blog/why-replace-zookeeper-with-kafka-raft-the-log-of-all-logs/
1. Why replace ZooKeeper?
In 2012, the Kafka controller for intra-cluster replication started development, with a single node elected as the controller within each cluster through ZooKeeper watchers.
The controller stores cluster metadata, such as broker IDs, racks, topic and partition details, leader information, and ISR details, in ZooKeeper as the source of truth. It also sets up watchers on ZooKeeper.
Non-controller brokers also directly interact with ZooKeeper to monitor metadata changes.

Problem:
The number of brokers and the number of topic partitions increase => Scalability bottlenecks related to the read and write traffic on ZooKeeper.
1.1 (Old) controller scalability limitation: broker shutdown
The leader sends a request to the controller.
Controller figure out which topic partitions the broker currently hosts and then tries to update the metadata. It also needs to select a new leader for those hosted topic partitions on the old leader and update metadata and ISR.
The controller propagates the new metadata to all brokers.
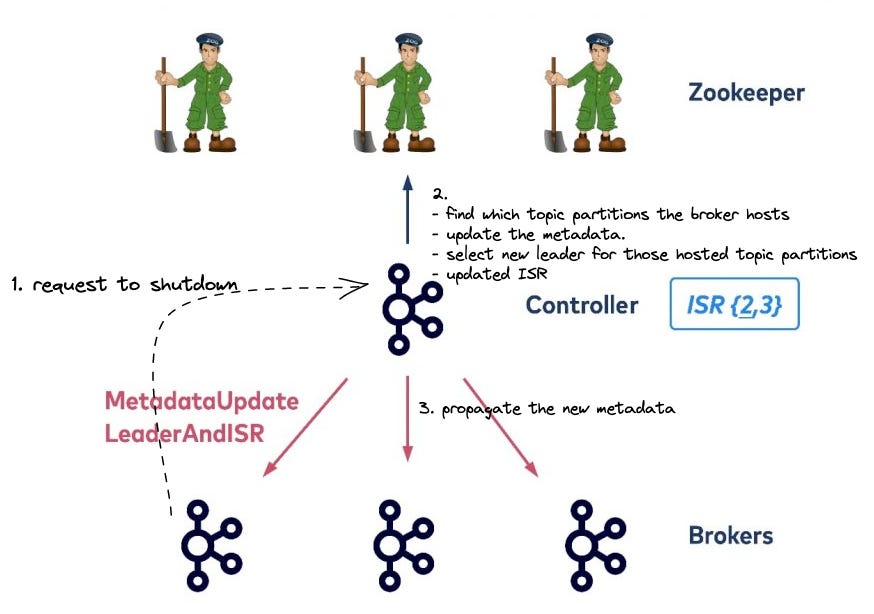
Problem: If we have thousands of topics on the shutdown broker, the controller has to write to ZooKeeper for each of the hosted partitions. It could take seconds or even more.
1.2 (Old) controller scalability limitation: controller failover

Old controller unexpectedly crashes.
ZooKeeper watcher will fire, and all brokers will be notified.
Other brokers will try to register themselves with ZooKeeper and whoever gets there first will become the new controller.
A new controller will do to fetch metadata from ZooKeeper. It will be a bottleneck when a large number of topic partitions in the cluster.
2. Why choose KRaft?
Find a solution that will stand up to thousands of brokers and millions of partitions.
What do we store in Zookeeper?
Metadata => sequence of the metadata change events => aka metadata log
Why not store metadata log in Kafka itself?
Metadata changes propagation => brokers replicating the metadata changelog instead of via RPCs
Each broker has local metadata that would eventually be consistent.
A quorum of controllers instead of a single controller => failover in a short time
2.1 Primary-backup vs. quorum replication

A single leader:
Replica takes all of the incoming writes
Tries to replicate them to other replicas
Waiting for all ack => treat as committed => return clients
Kafka’s failure mode is f + 1. (It means to tolerate f consecutive failures, we need f + 1 replicas)

A single leader:
take writes, and then replicate to followers.
only waits for the majority of replicas
after getting quorum => treat as committed => return to clients
Kafka’s failure mode is 2f + 1. (It means to tolerate f consecutive failures, we need 2f + 1 replicas)
2.2 KRaft – Kafka Raft implementation
Use quorum replication
KRaft, which follows the Raft algorithm to achieve quorum replication.
Leader election
Leader election is implemented using Kafka leader epochs. This ensures that only one leader is elected in each epoch.
Brokers have three roles:
leader (in quorum)
voter (in quorum)
observer (passive read the replicated log to catch up with the quorum)
First step: all brokers initialized as voters

Second step: finding the leader.
A voter could bump up to a new epoch.
Each voter will check
if own_epoch > epoch_in_request OR already voted OR local_log > candidate's_local_log: does NOT grant its vote to the candidate else: grant the vote
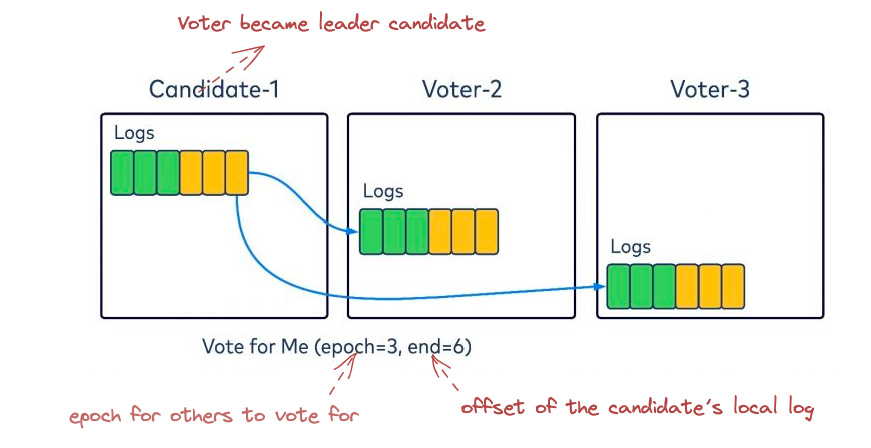
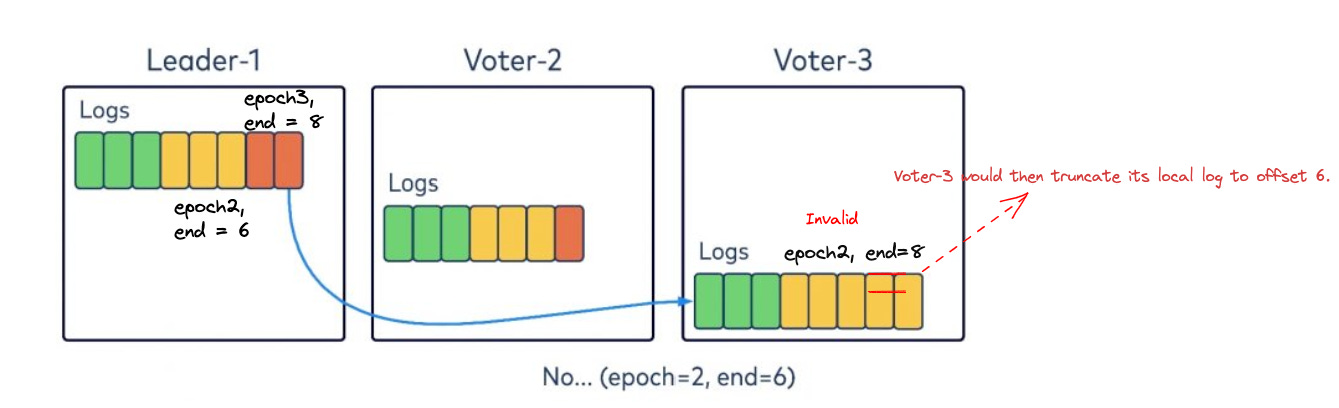
Log replication
KRaft aligns with a pull-based replication mechanism.

2.3 Quorum controller
A small subset of the total number of brokers gets configured as a quorum.
Using the KRaft algorithm to elect a leader => Quorum’s controller. It is responsible for the following:
taking new broker registrations.
detecting broker failures.
change cluster metadata.

(NEW quorum controller): broker shutdowns

(NEW quorum controller): controller failover

An Experiment: ZooKeeper vs. Quorum Controller
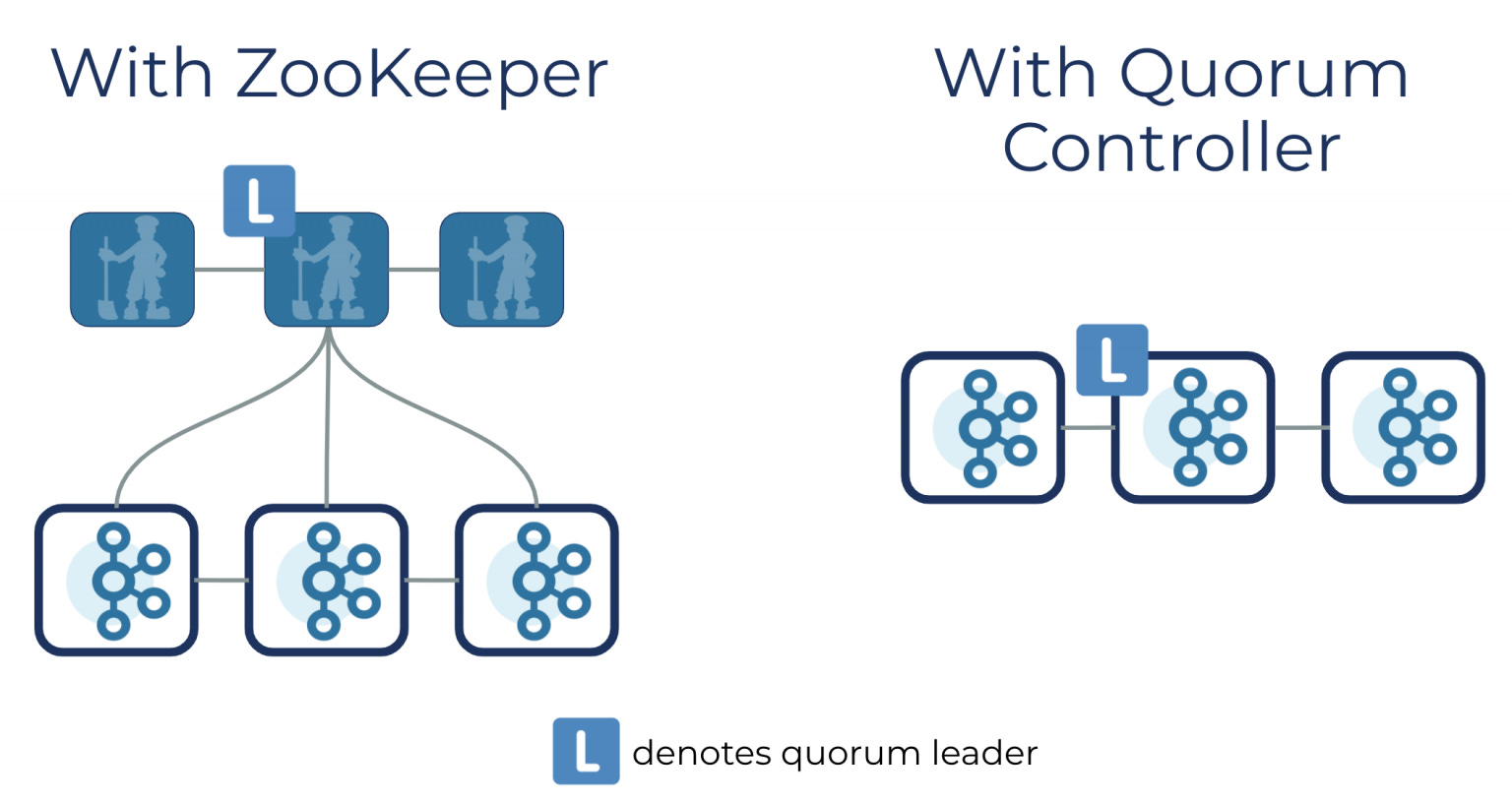

It’s more efficient to maintain metadata as a log of events, just as we do with all other data in Kafka.
By leveraging the metadata log in the construction of the Quorum Controller, we can overcome scalability limitations and support millions of brokers and partitions in a single Kafka cluster.